
ChatGPT, Claude, Gemini, Grok, Llama, and the other major AI models you use every day are not finished products. They improve continuously — and a significant part of that improvement comes from human feedback provided by remote workers. This guide explains how that process works, what the tasks actually involve, and how to build a profile that gets you matched with AI model improvement work.
How human feedback improves AI models
AI models like ChatGPT are trained on large amounts of text, but text alone does not teach a model what makes a response helpful, accurate, or safe. For that, AI companies use a process called reinforcement learning from human feedback (RLHF). Human reviewers — often remote contractors — rate model responses, compare competing answers, rewrite poor outputs, and flag safety issues. This feedback is structured into training signal that teaches the model what better behavior looks like.

This loop repeats continuously. As models get better, the evaluation problems get harder — which is why the demand for thoughtful, well-qualified human reviewers has not decreased as AI has improved. Better models need better feedback to keep getting better.
You do not work directly with the AI labs in most cases. The work is typically accessed through platforms and staffing partners — Mercor, Outlier AI, Handshake AI, DataAnnotation.tech, and others — that manage the workflow between remote workers and the AI companies or enterprise AI teams that need human feedback.
The common paid AI review tasks

- Rank two answers — You see two AI responses to the same prompt and choose the better one. The platform uses your choice as a preference signal. This is the most common task type and the clearest test of whether your judgment aligns with what the model needs.
- Apply a rubric — Score a response using a structured set of quality criteria (accuracy, helpfulness, clarity, safety, completeness). Consistency matters more than speed here — the platform compares your scores against other reviewers to verify your calibration.
- Rewrite a response — Take a weak AI answer and improve it. Fix inaccuracies, improve clarity, restructure the argument, or correct the tone. This task rewards writing skill and editorial judgment.
- Verify facts — Check whether specific claims in an AI response are accurate. This requires research habits and the ability to recognize when a fact needs verification versus when it can be accepted as stated.
- Review code or math — Evaluate whether generated code runs correctly, whether a mathematical solution is valid, or whether an algorithm is implemented properly. Requires technical domain skill and is among the higher-paying task types.
Key pattern: Higher-value work requires both subject expertise and written reasoning. The platforms that pay the most want to know not just what you chose, but why you chose it.
Where your expertise fits in
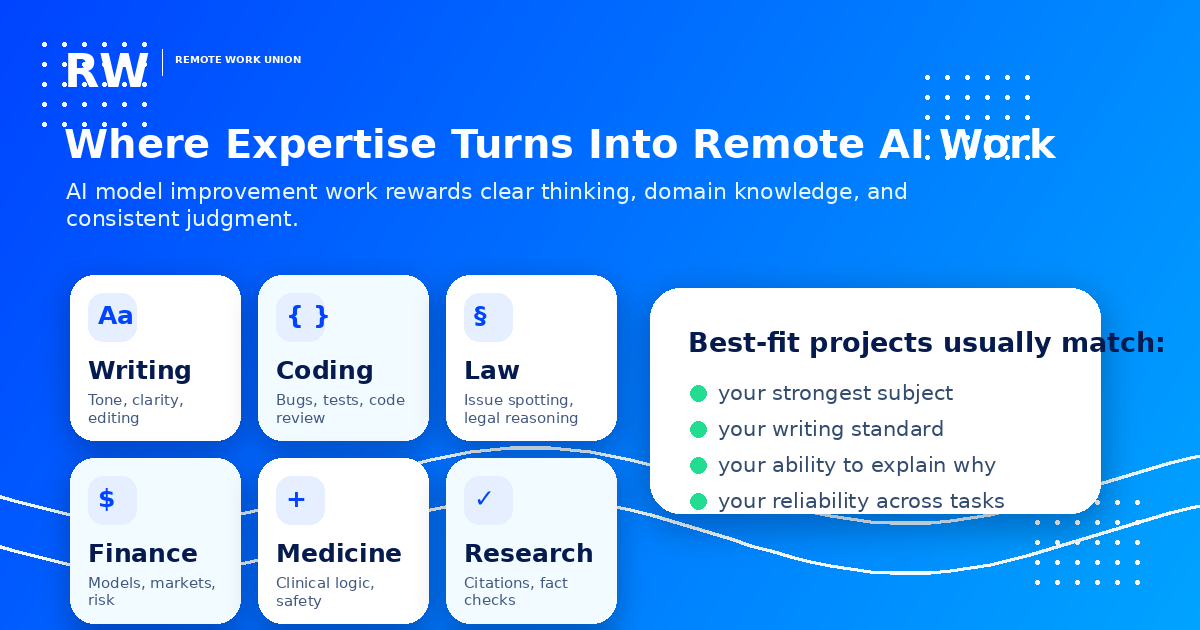
The AI model improvement ecosystem needs people from many different backgrounds because AI models answer questions about everything. Each domain has tasks that require real knowledge to evaluate properly:
- Writing — Tone, clarity, grammar, audience fit. Writers evaluate whether model output reads naturally and communicates effectively.
- Coding — Bugs, test coverage, code review. Engineers and developers test whether generated code is correct and production-ready.
- Law — Issue spotting, legal reasoning, citation accuracy. Lawyers and paralegals verify whether legal explanations apply the right rules.
- Finance — Financial models, markets, risk. Finance professionals check whether investment and accounting explanations are sound.
- Medicine — Clinical logic, safety, terminology. Medical professionals evaluate whether health-related AI output is accurate and safe.
- Research — Citations, fact checks, source evaluation. Researchers verify whether AI output represents its sources accurately.
Best-fit projects match your strongest subject, your writing standard, your ability to explain why a judgment is correct, and your reliability across tasks. Platforms use profile information and assessment results to make these matches. The more specifically you communicate your domain, the better the match quality.
The 4-step profile ladder for better projects
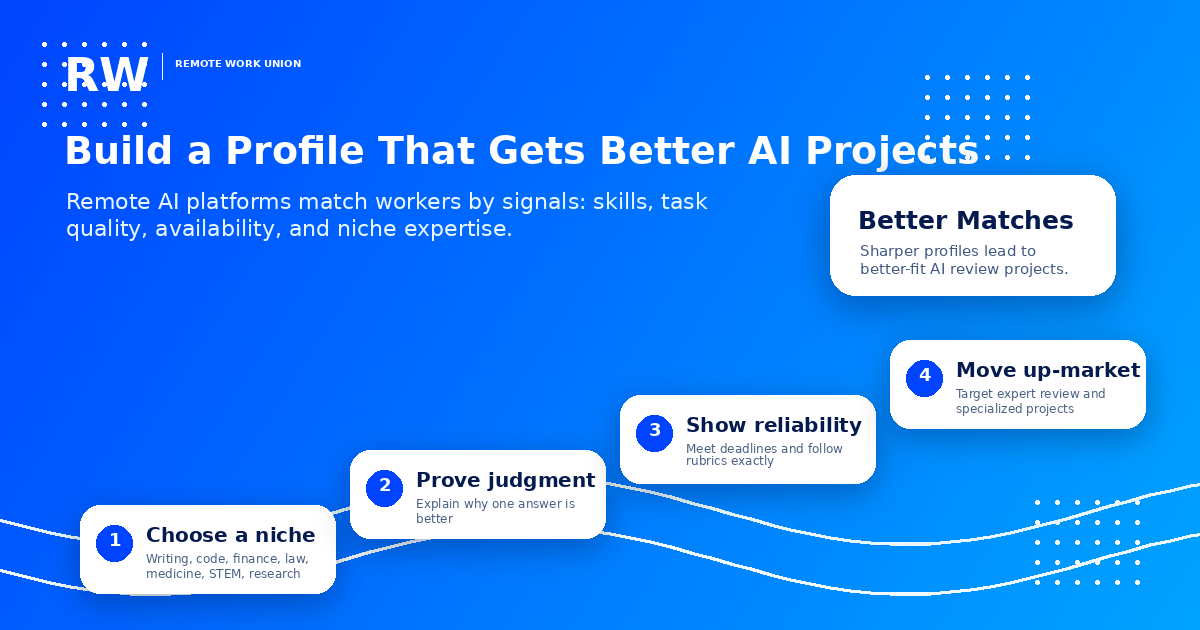
Step 1: Choose a niche
Pick your strongest subject area — writing, code, finance, law, medicine, STEM, or research — and build your profile around it explicitly. Platforms match workers to projects partly by the domain tags in their profile. A profile that says "I can evaluate investment and accounting AI answers" will be matched to finance projects faster than one that says "I'm good at many things."
Step 2: Prove judgment
Demonstrate the ability to explain why one answer is better than another with specific reasoning. This is tested in every platform assessment. Prepare 2–3 examples in your head: a situation where you identified a factual error, a case where a technically correct answer still failed the user's intent, a moment where you recognized a safety issue that was not obvious. These become the core of strong assessment submissions.
Step 3: Show reliability
Meet deadlines and follow rubrics exactly. Platforms track reliability scores alongside quality scores. Consistent, on-time work that follows project rules — even when the rules feel overly specific — is what builds the trust that unlocks better project access.
Step 4: Move up-market
Once you have a track record on general projects, explicitly target expert review and specialized projects. Update your profile to reflect your domain depth. Apply to higher-tier assessments. The path from general evaluator to domain expert reviewer is primarily a track record problem, not a credentials problem.
Remote Work Union organizes AI model improvement roles by background — find your match without hunting through every platform.
Find Roles Hiring Now →Which platforms connect workers to AI model improvement work
The major AI companies — OpenAI (ChatGPT), Anthropic (Claude), Google DeepMind (Gemini), xAI (Grok), Meta (Llama), Microsoft (Copilot) — all use human feedback in model development, but most of this work reaches remote contractors through intermediary platforms rather than direct company hiring.
The core platforms for AI model improvement work are Handshake AI (fellowship model, good for academic and specialist backgrounds), Mercor (AI interview matching, strong for technical and expert backgrounds), micro1 (AI-interview matching for expert AI training projects), and Outlier AI (broad task types, accessible entry). DataAnnotation.tech, Alignerr, Turing, and Mindrift also offer relevant projects. A full breakdown of which platform fits which background is in the Remote Work Union platform guide.
Final takeaway
The AI models millions of people use every day get better because remote workers provide structured human feedback. That feedback work is real, it pays well for people who bring genuine domain knowledge, and the demand for it is growing as the models become more capable and the evaluation problems become more complex.
The path in is straightforward: choose a niche, prove judgment, show reliability, and move up-market toward the projects that match your expertise. The platforms exist. The work is real. The only variable is how specifically you can communicate what you are able to evaluate.
Frequently asked questions
Can I get paid to improve ChatGPT or Claude?
Yes. AI companies like OpenAI (ChatGPT), Anthropic (Claude), Google (Gemini), xAI (Grok), and Meta (Llama) all use human feedback to improve their models. The work is typically accessed through platforms like Mercor, Outlier AI, Handshake AI, and DataAnnotation.tech rather than directly through the AI companies themselves.
What tasks are involved in improving AI models remotely?
Common tasks include ranking two answers (preference signal), applying a rubric (consistency), rewriting a weak response (writing skill), verifying facts (research), and reviewing code or math (domain skill). Higher-value work usually requires both subject expertise and written reasoning to explain your judgments.
How do I build a profile for AI model improvement work?
Four steps: (1) Choose a niche — writing, code, finance, law, medicine, STEM, or research; (2) Prove judgment — show you can explain why one answer is better with specific reasoning; (3) Show reliability — meet deadlines and follow rubrics exactly; (4) Move up-market — target expert review and specialized projects as your track record grows.
Which AI companies hire remote workers to improve their models?
OpenAI, Anthropic, Google DeepMind, xAI, Meta, Microsoft, Amazon, Mistral, Cohere, and Perplexity all use human feedback in model development. Most of this work is accessed through intermediary platforms and staffing partners rather than direct company hiring.