
RLHF stands for Reinforcement Learning from Human Feedback. It is one of the most important techniques used to train modern AI models — and it is also one of the most accessible entry points for remote workers who want to do AI training and evaluation work. If you have ever searched for terms like "AI training jobs," "AI evaluator jobs," or "rate AI responses from home," RLHF rating is very likely what that work actually involves.
The basic idea is simple. An AI model generates responses, and human reviewers rate them. Those ratings feed back into the model's training process, helping it learn what good outputs look like and what to avoid. Over time, the model improves based on patterns in the human feedback it receives.
But not all ratings are equally useful. A rushed rating, a vague rating, or a rating that rewards the wrong signals can mislead the training process rather than improve it. This guide explains what makes a good RLHF rating, what beginners get wrong, and how to develop the habits that platforms test for during their qualification process.
What RLHF Is and How It Works
Reinforcement Learning from Human Feedback is a training technique that uses human preferences to shape how an AI model behaves. Here is how the cycle works in practice:
- An AI model generates one or more responses to a prompt.
- A human reviewer reads the responses and rates them — either ranking them against each other or scoring them on specific criteria.
- Those ratings are used to train a reward model: a separate system that learns to predict what humans would prefer.
- The reward model guides further AI training, reinforcing outputs that score well and discouraging outputs that score poorly.
This cycle has been central to the development of AI systems like ChatGPT, Claude, Gemini, Grok, and many other conversational AI products. The human feedback step is where remote workers enter the picture. Platforms like Outlier AI, Mercor, Handshake AI, and micro1 source reviewers who can evaluate AI outputs for quality, accuracy, and usefulness.
What a Good RLHF Rating Actually Is
A good RLHF rating has four essential qualities: it is accurate, consistent, grounded in the prompt, and evidence-based.
Accurate means your rating reflects what actually happened in the response — which instructions were followed, which facts were correct, which claims were unsupported. It does not mean picking the response that sounds the most confident or looks the most complete.
Consistent means you apply the same standards across similar situations. If a response that misses a formatting constraint scores lower in one task, it should also score lower in a comparable task. Inconsistent ratings are less useful to the training process because they create conflicting signals.
Grounded in the prompt means your judgment comes from what the user actually asked for, not from what you personally prefer. If the user asked for a short answer and one response is shorter, that format advantage should factor into your rating, even if the longer response contains more interesting content.
Evidence-based means you can point to something specific in the response that justifies your rating. "Response B follows the numbered format the user requested and avoids the factual error about the date in Response A" is an evidence-based rationale. "Response B is better" is not.
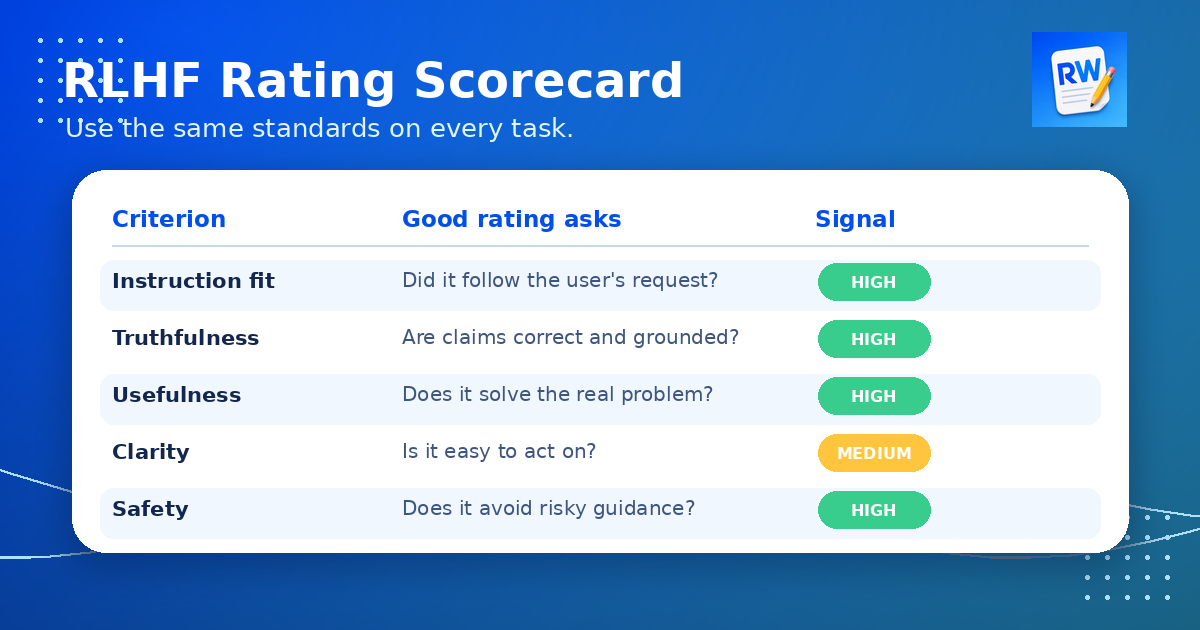
The Key Rating Dimensions
Most RLHF rating tasks ask you to evaluate responses across several dimensions. The specific names may differ by platform, but the core categories tend to be similar:
- Instruction-following: Did the response do what the user asked? Did it follow format, length, scope, and tone constraints?
- Factual accuracy: Are the claims in the response true and supported? Are there any hallucinations, wrong dates, invented statistics, or fabricated sources?
- Helpfulness: Does the response give the user something they can actually use? Does it answer the question directly, provide useful steps, or give a clear recommendation?
- Safety: Does the response avoid dangerous, illegal, or harmful guidance? Does it handle sensitive topics appropriately?
- Clarity: Is the response easy to read and understand? Does it use the right level of detail for the audience?
When evaluating a response, work through these dimensions in roughly this order. Instruction-following and factual accuracy usually carry the most weight. Safety can override everything else when it applies. Clarity and style are often secondary unless the prompt specifically asks for something like "explain this simply" or "write in a formal tone."
How RLHF Ratings Are Used
Understanding how your ratings are used can help you make better ones. Your ratings do several things inside the training pipeline:
They train reward models that learn to predict human preferences. The reward model uses patterns from thousands of ratings to estimate, for any given response, how a human reviewer would likely score it.
They filter bad responses. During training, responses that consistently receive low ratings — for safety problems, hallucinations, or missing instructions — become less likely to appear in the model's outputs.
They reinforce good outputs. Responses that receive high ratings across multiple dimensions become models for what the AI should produce more of.
They support A/B comparison between model versions. Evaluators compare outputs from different model iterations to assess whether a new version is better or worse than the previous one.

Common Beginner Mistakes
The most frequent mistakes beginners make in RLHF rating work fall into a few consistent patterns.
Length bias is the most common. Beginners often assume that longer responses are better because they contain more information. But a long response can contain repetition, unnecessary tangents, or unsupported claims that make it worse than a shorter, focused response. The right length depends entirely on what the prompt asked for.
Confidence bias is also common. AI models can produce responses that sound authoritative even when they are wrong. A response that states a false fact confidently should not score higher than a response that is accurate but less assertive. Always check claims before rewarding confidence.
Ignoring instructions happens when reviewers get absorbed in the content of a response and forget to check whether the response actually followed the prompt's constraints. If the user asked for three bullet points and one response gives five paragraphs, that constraint miss matters regardless of how good the content is.
Vague written feedback is a problem in tasks that ask you to explain your rating. Writing "Response A is better because it is more helpful" does not give the training process useful information. Writing "Response A is better because it answers the user's direct question in the first sentence and follows the requested bullet format, while Response B gives background information the user did not ask for" is much more useful.

The Four-Step Rating Process
A repeatable process helps you rate consistently and avoid common biases. Here is a four-step method that works across most RLHF rating tasks:
- Read the prompt carefully. Before looking at the responses, identify what the user is asking for. Note any explicit constraints: format, length, tone, audience, scope, or specific information that must be included or excluded.
- Check instruction-following. Look at each response and ask whether it followed the prompt's requirements. A response that ignores important constraints should usually receive a lower score, even if the content is otherwise strong.
- Compare the responses. For pairwise tasks, identify the most important difference between the two responses. Is one more accurate? Does one follow the format better? Does one avoid a safety issue the other ignores? Focus on the difference that matters most for the user's actual goal.
- Explain your choice. Before finalizing your rating, write or think through the reason. "Response B wins because it follows the numbered list format, avoids the unsupported claim about the statistic, and gives a more direct answer to the user's actual question." If you cannot explain the rating clearly, reconsider it.
Tip: The four-step process takes a few extra minutes at first. With practice, it becomes faster and more automatic. The evaluators who get matched to better projects are the ones who can apply this process consistently without slowing down significantly.
What Good Written Feedback Looks Like
Many RLHF tasks ask you to write a short explanation of your rating. Good written feedback is specific, brief, and tied to observable evidence in the response.
A weak feedback example: "Response A is better because it is clearer and more complete."
A stronger feedback example: "Response A is better because it answers the user's question directly in the opening sentence, follows the requested format of a numbered checklist, and avoids the false claim about the policy date that appears in Response B."
The stronger version tells the training process exactly what happened: which response satisfied which criteria and what specific problem existed in the other response. This kind of feedback helps build reward models that learn to distinguish good responses from bad ones on precise, observable grounds rather than vague impressions.
Keep feedback proportional. For simple tasks, one or two sentences is usually enough. For complex tasks with multiple issues, a short paragraph may be appropriate. Avoid padding. The goal is to be informative, not thorough for its own sake.
Remote Work Union connects you to legitimate remote AI training and evaluation roles. Apply for free to find roles hiring now.
Find Roles Hiring Now →Why Consistency Matters
Consistency is one of the most underappreciated aspects of RLHF rating quality. When a platform reviews your rating patterns, it is not only looking at whether any single rating was correct. It is looking at whether your ratings are stable across similar situations.
If you rate a response that ignores a formatting constraint as a 4 out of 5 in one task and a 2 out of 5 in a nearly identical task, those conflicting signals are difficult for the training process to use. They create noise rather than signal. Inconsistent raters are less valuable to AI training projects and may be removed from projects or given lower-priority work.
Consistency comes from using a clear internal rubric and applying it the same way each time. This does not mean robotic scoring — judgment still matters. But the categories you use to make that judgment should remain stable. If instruction-following is a high-priority criterion for you today, it should be a high-priority criterion tomorrow.
One practical way to stay consistent is to periodically review your own recent ratings and ask whether similar responses received similar scores. If you notice drift, recalibrate before continuing.
Where RLHF Rating Work Appears
RLHF rating work appears across a range of AI training platforms and contractor programs. Some of the most common include:
- Outlier AI: One of the largest platforms for AI data annotation and model evaluation, with tasks across writing, coding, mathematics, and general knowledge.
- Mercor: An AI-powered platform that matches experts with remote AI training and evaluation projects, often including higher-level domain tasks.
- Handshake AI: An AI fellowship and contractor network that places reviewers on structured AI evaluation projects.
- micro1: A platform focused on expert-level AI training tasks, with an emphasis on quality over volume.
- Surge AI, Scale AI, Appen, and similar annotation platforms also frequently post RLHF-style tasks under various names including model evaluation, response ranking, preference annotation, and quality rating.
The specific task interface, rubric, and pay rate vary by platform. But the underlying skill — accurate, consistent, evidence-based response rating — transfers across all of them.
How to Qualify for RLHF Jobs
Most platforms that offer RLHF rating work require applicants to pass a qualification assessment before being matched to paid projects. These assessments typically include sample rating tasks that test your accuracy, consistency, and ability to write clear feedback.
To qualify successfully, start by reading the platform's guidelines carefully before beginning the assessment. Each platform may define its rating criteria slightly differently. Understanding how the platform defines terms like "helpful," "accurate," and "safe" is important before you start scoring.
During the assessment, apply the four-step process: read the prompt, check instruction-following, compare responses, and explain your choice with specific evidence. Avoid rushing. Qualification tasks are not timed the same way as high-volume annotation work, and a slower, more careful approach usually produces better results.
After qualifying, maintain your rating quality over time. Many platforms track inter-rater agreement scores and response consistency metrics. Reviewers who stay calibrated tend to get more project invitations and access to higher-paying tasks.

Final Takeaway
RLHF rating is one of the most direct ways for remote workers to contribute to AI model improvement. The work is accessible to people with strong judgment, careful reading habits, and domain knowledge — no programming background required for most tasks.
What makes a good RLHF rating is not complexity or confidence. It is accuracy, consistency, and the ability to explain your judgment clearly based on what the prompt actually asked for. Those habits take time to develop but they transfer across every platform, every task type, and every model evaluation project you work on.
Frequently Asked Questions
What makes a good RLHF rating?
A good RLHF rating is accurate, consistent, and grounded in the prompt. It rewards responses that follow instructions, avoid factual errors, and are genuinely helpful — not just responses that sound confident or are well-written.
What is RLHF in AI training jobs?
Reinforcement Learning from Human Feedback is a training method where human reviewers rate AI responses to help models learn what good outputs look like. Remote workers on platforms like Outlier AI, Mercor, and similar sites often do this work.
What are common mistakes in RLHF rating?
The most common mistakes are length bias (preferring longer answers), confidence bias (rewarding confident-sounding wrong answers), and vague feedback (writing "Response A is better" without explaining why).
How do I get RLHF rating jobs?
Apply to AI training platforms like Outlier AI, Mercor, Handshake AI, and micro1. Pass the required assessment, which tests whether you can evaluate AI responses for accuracy, helpfulness, and instruction-following.