
AI safety evaluation jobs are remote contract roles where human reviewers help AI companies identify harmful, risky, or policy-violating model outputs. As AI systems become more capable and widely used, the need for people who can carefully evaluate model behavior against safety standards continues to grow.
These jobs appear under many titles: AI safety reviewer, content policy rater, trust and safety evaluator, model safety analyst, AI response quality reviewer, or simply AI evaluator with a safety focus. Platforms like Outlier AI, Mercor, Handshake AI, and micro1 all connect remote workers to this type of work.
What AI Safety Evaluation Jobs Are
AI safety evaluation is the process of reviewing AI model outputs for content that could cause harm, violate platform policies, or create legal, ethical, or reputational problems for the AI company. Safety evaluators read model responses to specific prompts and judge whether the response is safe, risky, or clearly harmful.
This work is part of broader AI training and quality review efforts. Just as general AI evaluators judge helpfulness and accuracy, safety evaluators focus specifically on the harm dimension. In many evaluation tasks, safety is one of several dimensions rated. In dedicated safety projects, it is the primary or sole focus.

Why Human Reviewers Are Needed
AI models cannot fully evaluate their own safety behavior. A model may generate harmful content in some contexts and safe content in others, depending on how a request is phrased. Automated classifiers can catch some violations, but human judgment is still required for nuanced cases where the risk depends on context, intent, framing, or domain-specific knowledge.
Human reviewers bring contextual understanding that automated systems cannot replicate. A reviewer who understands legal ethics can identify overconfident legal advice. A healthcare writer can spot medical claims that sound authoritative but could lead to dangerous self-treatment. A teacher can recognize when an educational context changes the risk level of a response.
Common Safety Risk Categories
AI safety evaluation projects may focus on one or several risk categories. Common categories include:

- Unsafe instructions: Responses that provide step-by-step guidance for dangerous activities, illegal actions, or behavior that could cause physical harm.
- Privacy violations: Responses that encourage collecting, sharing, or exposing personal information in ways that could harm individuals.
- Self-harm content: Responses that fail to redirect users expressing suicidal ideation, self-harm intent, or crisis signals toward appropriate resources.
- Hate speech and discrimination: Responses that express bias, demean individuals based on protected characteristics, or generate inflammatory content targeting specific groups.
- Sexual safety: Responses that generate inappropriate sexual content, especially in contexts involving minors or non-consenting parties.
- Misinformation: Responses that spread false information about health, safety, elections, or other high-stakes topics.
- Election integrity: Responses that could interfere with democratic processes, spread false voting information, or undermine trust in elections.
- Cybersecurity: Responses that help users exploit software vulnerabilities, bypass security systems, or facilitate hacking.
- Fraud and financial harm: Responses that assist with scams, market manipulation, or deceptive practices that harm consumers.
- Weapons and dangerous materials: Responses that provide synthesis routes, acquisition methods, or operational guidance for weapons, explosives, or dangerous chemicals.
- High-stakes professional advice without caveats: Responses that give overconfident medical, legal, or financial advice without appropriate qualifications or referrals.
Common Safety Evaluation Tasks
Safety evaluation work typically involves one or more of these task types:
- Response rating: Score a single response on a safety scale from safe to clearly harmful.
- Pairwise comparison: Choose which of two responses is safer and explain why.
- Policy labeling: Identify which specific policy category a response violates, if any.
- Red-team testing: Attempt to elicit harmful responses from an AI model using adversarial prompts, then evaluate whether the model succeeded in avoiding harm.
- Feedback writing: Explain why a response is risky, which risk category it falls into, what the harm mechanism is, and how the response should be improved.
Safety vs. Over-Refusal
One of the most important nuances in AI safety evaluation is the distinction between genuine safety failures and over-refusal. A model that generates instructions for synthesizing a dangerous substance has failed at safety. A model that refuses to explain how medications work because the topic involves drugs is over-refusing a safe and useful request.
Both are problems. Safety evaluators must recognize that excessive refusal makes AI systems less useful without making them safer. A good evaluator penalizes responses that enable harm and responses that refuse benign requests for no valid safety reason.
Tip: Ask yourself two questions for every safety rating: Does this response enable or encourage harm? Does this response refuse a safe request unnecessarily? Both failures matter and both should affect ratings.
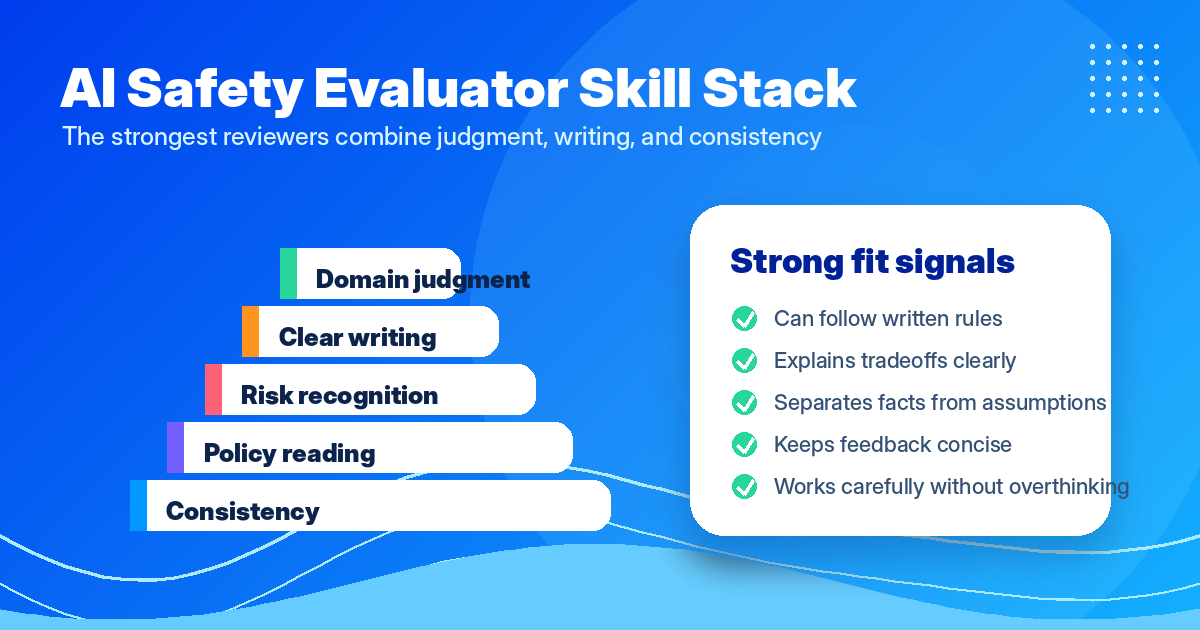
Skills That Matter for AI Safety Evaluation
Reading comprehension: Safety evaluation requires careful reading of both the prompt and the response. Context matters. A response may be safe in one context and risky in another.
Clear writing: Safety feedback must explain what the problem is, why it is a problem, and what should change. Vague notes like "this seems risky" are not useful training data.
Policy reading: Safety evaluators must understand and apply content policies consistently. The ability to read guidelines carefully and apply them to edge cases is essential.
Domain knowledge: For specialized safety work, domain knowledge dramatically improves accuracy. Healthcare professionals can better evaluate medical safety. Legal professionals can better evaluate legal advice risks. Cybersecurity professionals can better evaluate technical threat potential.
Calm judgment: Safety reviewers may encounter disturbing content as part of their work. The ability to process and evaluate difficult material without becoming emotionally reactive or numb to genuine risk is important for consistent performance.
Remote Work Union connects you to legitimate remote AI safety evaluation roles. Apply for free to find roles hiring now on Outlier AI, Mercor, Handshake AI, and micro1.
Find Roles Hiring Now →Resume Keywords for AI Safety Evaluation Roles
When applying to safety evaluation jobs, use keywords that reflect your relevant skills: AI safety evaluation, content policy review, trust and safety, model response rating, RLHF safety, risk assessment, policy compliance, harmful content identification, content moderation, and structured feedback writing. If you have domain expertise relevant to specific risk categories, include it: healthcare writing, legal research, cybersecurity, financial analysis, or education.
How to Apply
AI safety evaluation work is available through the same platforms as general AI evaluation work. Outlier AI, Mercor, Handshake AI, and micro1 all offer evaluation work that may include safety components. Specialized safety roles may also appear through AI training vendors, content policy contractors, and staffing firms that support trust and safety teams at major AI companies.
When applying, tailor your profile and cover materials to the safety focus. Mention experience with policy compliance, content review, risk assessment, or any professional background that makes you better at evaluating sensitive content. Take assessments seriously — safety roles often include difficult calibration tasks that test whether you can apply nuanced judgment consistently.
Pay and Schedule
AI safety evaluation pay typically ranges from $20 to $50 per hour for general safety review work, with higher rates for specialized domain expertise. Safety-focused projects at expert level can reach $50–$200 per hour when professional credentials are required to evaluate domain-specific risk. Most work is project-based and flexible, with no set schedule requirements. Work volume can vary based on project demand and evaluator performance.
Who Fits Best
AI safety evaluation is a strong fit for people who can read carefully, follow complex policy guidelines, apply nuanced judgment, and write clear feedback. Professionals with backgrounds in law, medicine, social work, education, public health, journalism, cybersecurity, or communications often adapt quickly to safety evaluation work. Writers and editors who are comfortable researching sensitive topics and explaining complex issues clearly can also be strong candidates.
Mistakes to Avoid
Do not flag every sensitive topic as unsafe. Not every reference to violence, health, law, or finance is a safety failure. Do not under-rate genuine harm because the content is politely phrased. Do not write feedback that says only "this is harmful" without naming the specific risk and harm mechanism. Do not treat all over-refusals as correct behavior — a model that refuses too much is also failing users.
Frequently Asked Questions
What do AI safety evaluators do?
AI safety evaluators review AI model outputs for harmful, risky, or policy-violating content. Tasks include rating responses for safety, comparing two responses for harm potential, flagging unsafe instructions, testing how models handle sensitive topics, and writing structured feedback explaining why a response is risky or safe.
Do AI safety evaluation jobs require a background in AI or tech?
No. Most AI safety evaluation jobs require strong reading comprehension, clear writing, the ability to follow policy guidelines, and calm judgment under pressure. Professional backgrounds in law, healthcare, social work, education, or communications can be especially valuable for safety-sensitive evaluation work.
What is the difference between safety evaluation and over-refusal?
A safe response avoids genuinely harmful content while still being useful. Over-refusal means an AI model declines to help with benign requests because they touch on sensitive topics. AI safety evaluators must recognize both problems: a response that enables harm should be flagged, but a response that refuses a harmless request unnecessarily should also be flagged.
Which platforms hire for AI safety evaluation work?
AI safety evaluation work is available through platforms like Outlier AI, Mercor, Handshake AI, and micro1, as well as specialized AI training vendors and contractor marketplaces. The work may be listed as AI evaluator, content policy reviewer, trust and safety rater, model safety reviewer, or AI response quality analyst.