
AI training is not only a technical process handled by engineers and researchers. Behind many modern AI systems is a large amount of human judgment: people reading model outputs, comparing answers, checking facts, tagging mistakes, applying rubrics, and deciding which response would be more useful to a real user.
That is why searches like AI training jobs, human feedback jobs, AI rater jobs, prompt evaluation jobs, data annotation jobs, and remote AI evaluator jobs keep showing up for people who want flexible online work. This guide explains how AI training works from a human feedback perspective — for remote job seekers who want to understand what the work actually looks like before applying.
What AI Training Means
AI training is the process of improving a model so it can produce better outputs. A model learns from data, examples, instructions, evaluations, and feedback. Some parts of that process are automated, but human review still matters because many useful qualities cannot be measured by a simple yes-or-no rule. A model can generate a grammatically correct response that is still incomplete, misleading, unsafe, vague, poorly organized, or not aligned with the user's intent. Human reviewers help identify those differences.
In remote AI training work, the human reviewer usually does not build the model itself. The reviewer acts as a quality judge — scoring responses, ranking two answers, rewriting a poor answer, labeling a category, checking whether a claim is supported, or explaining why one output is stronger than another.
The Basic Human Feedback Workflow
Most AI feedback projects follow a simple loop. First, there is an input: a prompt, task, document, image, code snippet, search question, customer support scenario, medical-style writing sample, legal question, finance explanation, education prompt, or some other piece of data. The AI model then produces one or more responses. A human reviewer evaluates the output — asking whether it is accurate, complete, whether it answers the exact question, whether it is safe, whether it is better than the alternative answer, whether it follows the project instructions. The review becomes a training signal, and the platform aggregates many human judgments to improve future model behavior.
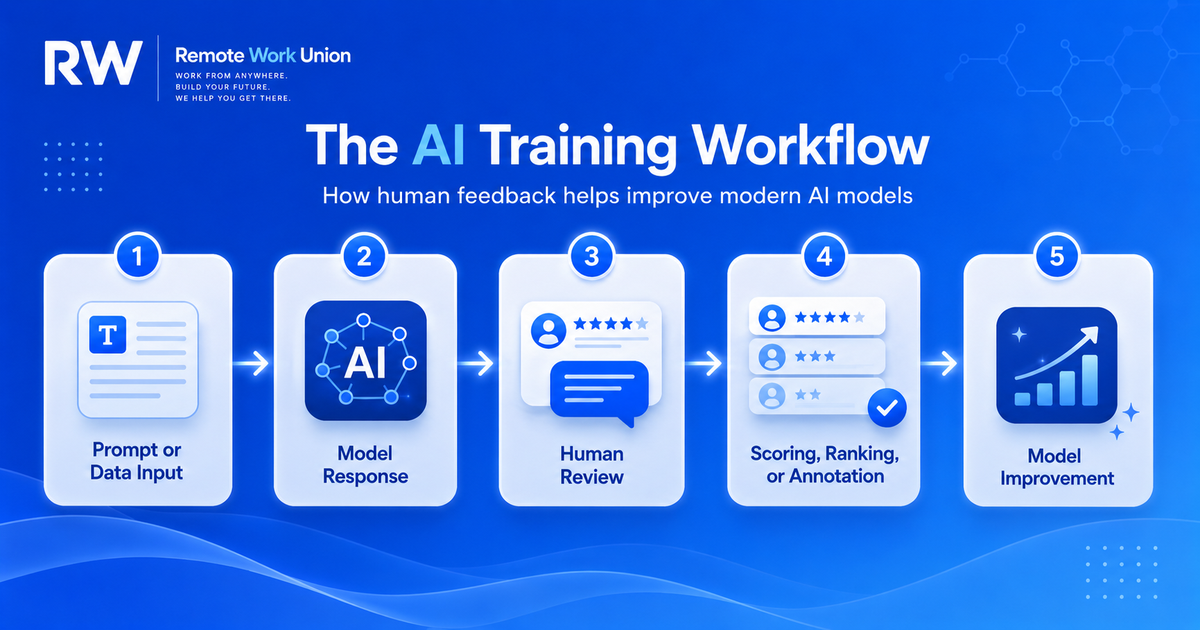
Where Human Feedback Fits Into Modern AI Models
Human feedback is especially useful after a model can already generate fluent text. At that stage, the question is no longer only whether the model can produce language — the harder question is whether the answer is useful, truthful, clear, safe, and aligned with what the user wanted. This is why RLHF (reinforcement learning from human feedback) became an important keyword in AI work. Humans compare outputs, those preferences help train a reward model or scoring system, and the AI system is nudged toward responses people judged as stronger.
Not every remote AI job is pure RLHF. Many roles are broader: AI data annotation, search evaluation, prompt evaluation, model response review, domain expert review, safety review, translation evaluation, coding evaluation, or fact-checking. But the common thread is the same: human judgment is used to improve machine-generated output.
Common Human Feedback Tasks
Remote AI training projects can vary, but most involve a few core task types. Rating responses is common when the platform wants a quick quality score. Ranking outputs is common when the system needs to know which of several answers is best. Annotation is common when the model needs structured labels — sentiment, topic, intent, entity type, error category, tone, safety classification, or relevance. Fact-checking and rubric scoring are higher-judgment tasks that often require careful reading, source checking, domain knowledge, or the ability to explain exactly why a response is correct or incorrect.

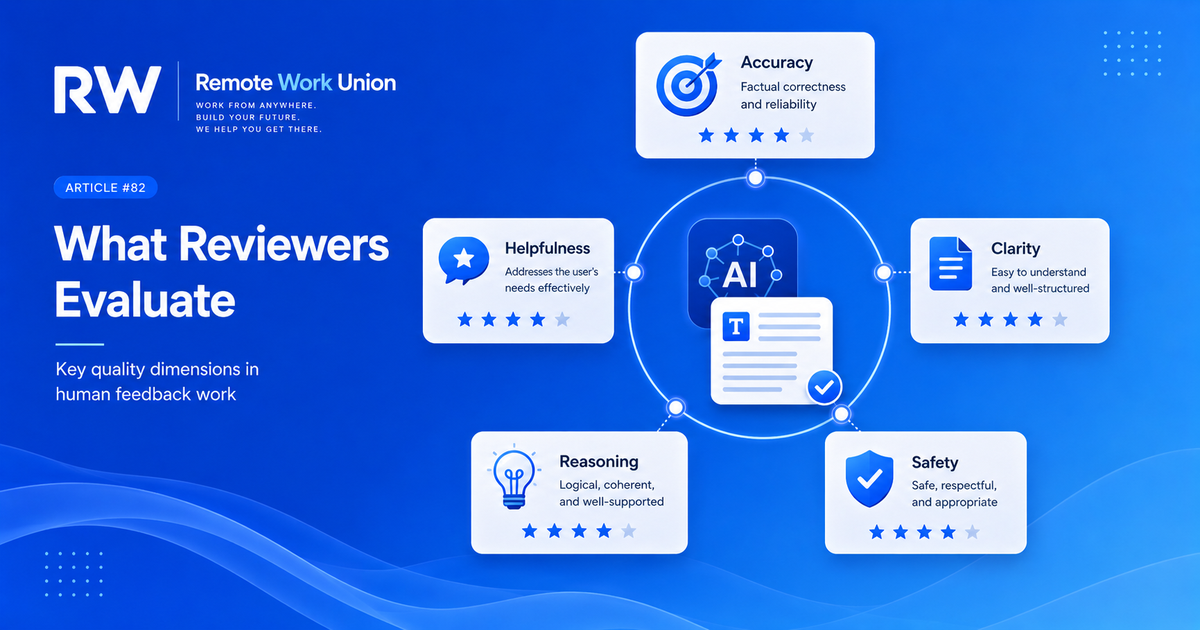
What Reviewers Evaluate
The best AI reviewers are not only looking for obvious mistakes — they are evaluating several quality dimensions at once. Accuracy means the response is factually correct and does not make unsupported claims. Helpfulness means the answer solves the user's actual problem instead of giving a generic response. Clarity means the response is easy to understand and logically organized. Reasoning matters when a task requires steps, comparison, tradeoffs, or judgment. Safety matters because AI systems need to avoid harmful, inappropriate, privacy-invasive, or misleading guidance. Many projects give reviewers a rubric defining what each score means for a specific quality dimension.
Remote Work Union connects you to legitimate AI training and human feedback roles. Apply for free.
Find Roles Hiring Now →Examples of Remote AI Training Roles
AI model evaluator jobs usually focus on judging model responses — you may compare two answers and choose the one that better follows the prompt. AI rater jobs may use rating scales for quality, relevance, safety, or satisfaction. AI response reviewer jobs often include editing, critique, and written explanations. Prompt evaluation jobs focus on whether a model handles a prompt well. Data annotation jobs may involve tagging text, images, search results, transcripts, or documents. Domain expert review jobs use professional knowledge in law, finance, healthcare, education, coding, science, writing, or business to judge specialized outputs.
Job titles change across companies and platforms. One platform may call the work AI trainer. Another may call it search quality rater, evaluator, annotation specialist, model response reviewer, expert reviewer, generative AI evaluator, or human feedback specialist. Job seekers should search across several terms instead of relying on only one title.
Skills That Matter Most
Strong reading comprehension is the foundation — reviewers need to understand the user's prompt, identify hidden requirements, and notice when an answer is only partially responsive. Clear writing also matters because many projects ask reviewers to explain their scores. Attention to detail is more important than speed at the beginning. Research skill helps with fact-checking and citation-sensitive tasks. Domain expertise helps when the prompt involves specialized knowledge.
How AI Training Work Is Usually Structured
Many remote AI training projects are contract-based. Workers may apply to a platform, complete a profile, take assessments, receive access to projects, and then work on tasks when they are available. Some projects pay hourly. Others pay per task, per accepted submission, or per unit of reviewed content. Instructions can change from project to project — one project might reward detailed explanations while another requires short labels only. Treat each project like a quality-control system, not like casual opinion work.
Why This Is Different From Basic Data Entry
Some job seekers search for data entry remote jobs because they want work from home with flexible hours and no phone calls. AI data annotation and AI evaluation can look similar from the outside because both involve online tasks. The difference is that AI feedback work usually asks for more judgment. Data entry is often about transferring information accurately. AI training work is often about deciding whether information is correct, useful, relevant, safe, or better than an alternative. That is why strong writers, editors, teachers, analysts, researchers, coders, legal professionals, healthcare writers, and finance professionals may find better opportunities in AI evaluation than in generic typing jobs.
How to Prepare a Strong Application
A strong application should show judgment, clarity, and reliability. Instead of saying only that you are interested in AI, describe the work you can do: evaluate model responses, compare outputs, apply rubrics, fact-check claims, annotate data, write concise feedback, and review answers for accuracy and helpfulness. Use keywords that match the role — for non-technical roles, include phrases like AI response review, model evaluation, data annotation, prompt evaluation, search evaluation, rubric scoring, written feedback, content quality, fact-checking, and remote AI training. If there is an assessment, slow down. Read the rubric, compare examples, watch for trick cases, and explain decisions in clear language.
Search Terms Job Seekers Should Use
The best search strategy combines broad AI keywords with specific task keywords. Useful searches include remote AI training jobs, AI model evaluator jobs, AI rater jobs, AI response reviewer jobs, prompt evaluation jobs, data annotation jobs from home, RLHF jobs, human feedback jobs, AI writing evaluator, AI fact-checking jobs, and generative AI evaluator. Company and product keywords can also help — search terms around OpenAI, ChatGPT, Anthropic, Claude, Google AI, Gemini, Microsoft AI, Copilot, Meta AI, and Amazon AI can surface articles, platform pages, job descriptions, and contractor projects. Use several search terms and save the ones that return real evaluation, annotation, or feedback work.
Frequently Asked Questions
Do you need to know how to code for AI training jobs?
Not always. Many AI feedback jobs are non-technical and focus on writing, research, language, judgment, or subject expertise. Coding roles exist, but they are only one part of the market.
Is AI training the same as data annotation?
Data annotation is one part of AI training. Some projects involve simple labels, while others involve comparing full answers, checking facts, evaluating reasoning, or rewriting responses.
Can beginners do AI training work?
Some entry-level projects are beginner-friendly, especially if the applicant can write clearly and follow instructions. Higher-paying or expert projects usually require stronger skills, domain knowledge, or better assessment performance.
Are AI training jobs remote?
Many projects are remote or work-from-home, but availability varies by platform, country, language, skill set, and project demand. Search for remote, contract, part-time, work from anywhere, and flexible AI evaluation roles.