
AI models can produce responses that sound completely authoritative while containing false information. This is one of the core challenges in AI model evaluation work — and it is one of the reasons that human fact-checkers are still essential to AI training and quality review projects.
When an AI response invents a statistic, cites a source that does not exist, gives a wrong date, or states a false claim with high confidence, a human reviewer needs to catch it. Platforms like Outlier AI, Mercor, Handshake AI, micro1, and many other remote AI evaluation services regularly test applicants on their ability to identify inaccurate outputs. Fact-checking is not a bonus skill — it is a baseline expectation for quality evaluation work.
This guide explains how AI hallucinations happen, what to look for, how to rate partially correct responses, how to write clear fact-check feedback, and how these skills translate directly into remote AI training jobs.
Why Fact-Checking Matters in AI Evaluation
AI models are trained on large amounts of text data. They learn to generate responses that sound plausible and match patterns from their training. The problem is that "sounds plausible" and "is accurate" are two different things. A model can produce a sentence that perfectly matches the style and structure of a factual claim without the underlying claim being true.
This matters enormously for users who rely on AI responses to make decisions — whether those decisions involve medical questions, legal research, financial planning, job applications, technical instructions, or simply factual questions about the world. A confident wrong answer is often more dangerous than a tentative uncertain answer, because users are less likely to verify claims that appear to be stated with authority.
For remote evaluators, the ability to distinguish accurate from inaccurate AI outputs is one of the most direct ways to improve the systems being trained. When you correctly identify a hallucinated claim and rate the response lower, you contribute signal that the training process can use to make future responses more reliable.
What Hallucinations Are
An AI hallucination is a confident-sounding but false claim generated by an AI model. The term comes from the model's tendency to "imagine" details that fit the pattern of the response rather than pulling from verified information.
Hallucinations can take several forms:
- Invented statistics: A model may cite a specific percentage, number, or figure that sounds precise and credible but has no real source. For example: "Studies show that 73% of remote workers prefer AI training tasks."
- Fake citations: A model may generate a plausible-sounding author name, publication title, and year — all of which are fabricated. The citation looks real but the source does not exist.
- Wrong dates: Specific dates for historical events, product releases, legislation, or company milestones may be off by years or entirely invented.
- Incorrect attribution: A quote or idea may be attributed to the wrong person, organization, or source.
- Plausible-sounding but incorrect claims: A model may state something that fits the topic and sounds like common knowledge but is factually wrong. For example, claiming that a policy applies universally when it varies by country or state.

Common Hallucination Red Flags
Not every factual claim in an AI response needs to be treated with suspicion. But certain patterns should prompt closer scrutiny:
Very specific numbers without context. If a response cites a precise statistic — especially one that is oddly specific, like "43.7% of users" or "a $2.3 trillion market" — without naming a source or year, that specificity without evidence is a warning sign. Real statistics come from real studies, and real studies are citable.
Named sources that seem obscure or hard to verify. A model may invent institutional names, journal titles, or report names that sound credible but cannot be found through a search. If a named source is not immediately recognizable and a quick check does not confirm its existence, flag it.
Confident claims about rapidly changing topics. AI models have training cutoffs. Claims about current laws, platform policies, pricing, product features, regulations, or recent events may be outdated or simply wrong. The more recent and specific the claim, the higher the risk.
Explanations that sound authoritative but conflict with common knowledge. Sometimes a hallucination contradicts something that is widely known and easy to verify. If an AI response states that a well-known company was founded in the wrong year, or attributes a famous invention to the wrong person, that is a detectable error — and catching it is part of your job as an evaluator.
Professional advice stated without appropriate caveats. A medical claim that applies a treatment universally without noting exceptions, or a legal claim that gives advice as if it applies in all jurisdictions, may not be technically "hallucinated" — but the overconfidence is a quality problem that should lower the response's rating.
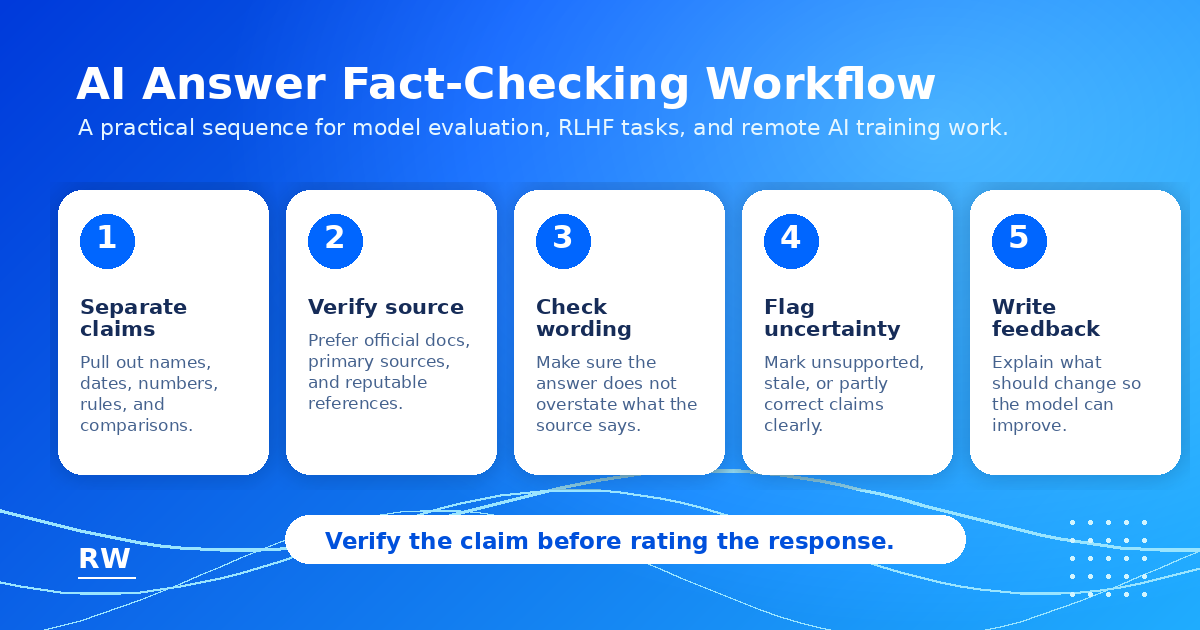
The Fact-Check Workflow
A structured workflow makes fact-checking more efficient and consistent. Here is a four-step process for evaluating factual accuracy in AI responses:
- Identify checkable claims. Read through the response and flag any specific fact that is verifiable: dates, names, statistics, citations, policies, prices, technical specifications, locations, and causal claims. You do not need to check every word — focus on claims that would change the usefulness or accuracy of the response if they were wrong.
- Check against known reliable information. For claims you can verify quickly, do so. For claims in your domain of expertise, apply your professional knowledge. For claims outside your domain, note that they are unverifiable by you and flag them accordingly. You do not need to be a universal expert — you need to be honest about what you can and cannot verify.
- Flag unsupported or suspicious claims. Any claim that seems specific but unverified, that contradicts what you know, or that fits the hallucination patterns described above should be flagged. You do not need to prove the claim is false — noting that a claim is unsupported or unverifiable is useful feedback on its own.
- Rate the response accordingly. A response with one minor factual error in an otherwise solid answer may receive a moderate deduction. A response where a central claim is hallucinated should receive a significant accuracy penalty, because the hallucination undermines the response's core usefulness.
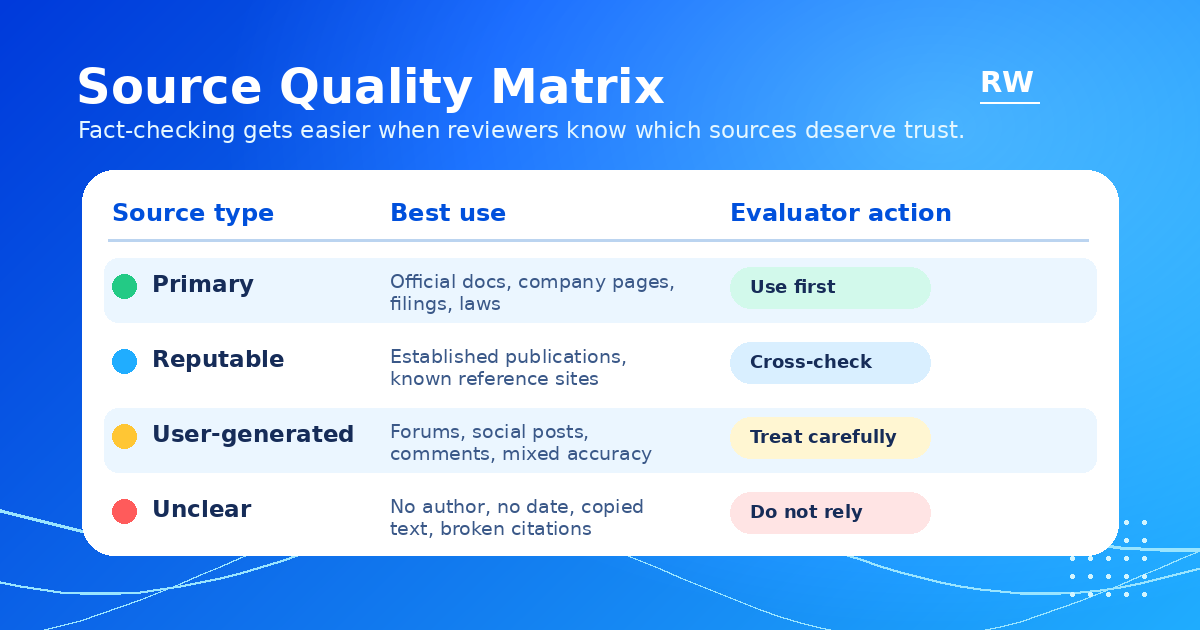
Source Quality and Claim Reliability
Not all facts are created equal. When evaluating AI responses, it helps to think about the reliability of the claim as well as the presence of any supporting source.
Some claims are highly reliable because they are stable, widely verified, and easy to confirm: founding dates of major organizations, basic scientific principles, definitions of standard terms, names of well-known historical figures. These are low-risk facts that are unlikely to be hallucinated in obvious ways.
Other claims are higher risk: current statistics, recent policy changes, platform-specific rules, professional regulations, pricing information, and anything tied to recent events. These are areas where AI training data may be outdated and where the model is more likely to confabulate a plausible-sounding answer rather than accurately reflecting current reality.
When an AI response cites a source, ask whether the source is identifiable and appropriate. A well-known institution like a government agency, major research university, or established journal lends more credibility to a cited figure than an unnamed source or an obscure publication. A response that says "According to the World Health Organization..." is more traceable than "Studies show..." — even if you do not verify the citation directly.
Remote Work Union connects you to legitimate remote AI evaluation and fact-checking roles. Apply for free to find roles hiring now.
Find Roles Hiring Now →What to Do With Partially Correct Answers
Many AI responses are not entirely wrong — they are partially correct. A response may have three accurate facts and one hallucinated statistic. It may have the right general framework but the wrong specific date. It may be accurate about the main topic but overconfident about edge cases.
For partially correct answers, the key question is: does the error matter for the user's actual goal? A minor factual imprecision in a response that is otherwise useful may warrant a small deduction. A central claim that is wrong may warrant a major deduction, even if everything else in the response is fine — because the wrong central claim undermines the user's ability to rely on the response.
Here is a useful framework for rating partially correct responses:
- Error is peripheral and minor: Small accuracy deduction. Note the error in feedback but do not penalize the overall helpfulness score heavily if the core answer is sound.
- Error is in supporting detail: Moderate accuracy deduction. The response is still directionally useful, but the reviewer should flag the inaccurate detail so the training process can associate that detail type with closer scrutiny.
- Error is in a central claim: Significant accuracy deduction. Even if the rest of the response is well-written, a wrong central claim makes the response potentially misleading and should be rated accordingly.
- Error involves safety-sensitive information: High accuracy deduction and a safety flag. Medical, legal, financial, and safety-critical errors that could lead to harmful action should be treated as high-severity issues regardless of how minor the error might seem in isolation.
Tip: When in doubt about how severely to penalize a partial accuracy issue, ask whether the user would be misled into a worse decision or outcome because of the error. That impact assessment is usually the most useful guide to rating severity.
How to Write Clear Fact-Check Feedback
Good fact-check feedback is specific, concise, and tied to a concrete claim in the response. Vague feedback like "some facts may be inaccurate" does not help the training process. Precise feedback that identifies the specific claim and its problem does.
Here are several feedback templates for common fact-check situations:
For an invented statistic: "The response cites [specific claim, e.g., '67% of remote workers prefer X'] without a source. This figure appears unsupported and may be hallucinated. The accuracy rating should reflect that a central quantitative claim cannot be verified."
For a likely fabricated citation: "The response attributes a finding to [source name]. This source could not be verified through a search and may be fabricated. Responses that cite unverifiable sources should receive a significant accuracy deduction because users may attempt to rely on the citation."
For an incorrect date or name: "The response states [specific false claim]. The correct [date/name/detail] is [correct information]. This is a verifiable factual error that should lower the accuracy score."
For overconfident professional advice without caveats: "The response advises [specific action] without noting that this varies by [jurisdiction/platform/individual situation]. The lack of appropriate qualification makes the advice potentially misleading for users in different contexts."
For a claim you cannot personally verify: "The response makes a specific claim about [topic] that I was unable to verify from my knowledge. This claim is in a domain that warrants specialist review and should be treated as uncertain."

Uncertain Claims vs. Wrong Claims
There is an important difference between a claim that is uncertain and a claim that is wrong. Understanding this distinction helps you rate AI responses more fairly.
An uncertain claim is one where the AI response acknowledges that it may not have complete information, where current or authoritative data is not available, or where individual circumstances vary. "This may depend on your jurisdiction" or "As of my last update, the policy was..." are examples of uncertainty framing. These are not hallucinations — they are honest acknowledgments of limitations. Responses that frame uncertainty appropriately should generally receive credit for intellectual honesty, not penalized for not knowing everything.
A wrong claim is one where the AI response states something as fact that is actually false, without acknowledging any uncertainty. "The policy requires X" when the policy actually requires Y, or "This was founded in 1998" when the correct year is 2005, are examples of wrong claims. These should be penalized according to their severity and their impact on the response's usefulness.
The most problematic type of wrong claim is one that combines false information with confident framing. A model that says "Studies definitively show..." while citing a fabricated statistic is not just wrong — it is presenting fabricated information as established fact. This double failure deserves a more significant accuracy deduction than a wrong claim that is at least framed tentatively.
Where Fact-Checking Skill Applies
Fact-checking ability is useful across a wide range of AI evaluation and training work:
- General model evaluation: Most AI response rating tasks include accuracy as a core dimension. Being able to spot hallucinations quickly makes you a more effective evaluator across all domains.
- Medical and health AI review: Medical content is high-stakes. Wrong dosages, contraindications, or diagnostic claims can be genuinely harmful. Medical writers, nurses, pharmacists, and other healthcare professionals are especially valued for this work.
- Legal AI review: Legal claims vary significantly by jurisdiction and change over time. Lawyers, paralegals, and legal researchers who can identify overstated or jurisdiction-specific claims are in demand for legal AI evaluation.
- Finance AI review: Financial advice, tax rules, investment claims, and market statistics are common hallucination targets. Finance and accounting professionals are well-positioned to catch errors in this domain.
- Search quality rating: Search engine quality evaluation often involves assessing whether AI-generated or AI-assisted search results accurately represent verifiable information.
- Science and technical review: Researchers, engineers, and technical specialists can evaluate whether AI responses about their domain contain accurate technical claims, correctly describe processes, or misrepresent scientific findings.
Platforms like Outlier AI, Mercor, and Handshake AI, and micro1 all test fact-checking ability during their qualification processes. Developing a reliable, systematic approach to identifying hallucinations and inaccurate claims directly improves your chances of passing assessments and getting matched with quality evaluation projects.
Final Takeaway
Fact-checking AI answers is one of the highest-value skills in remote model evaluation work. AI systems can generate fluent, confident responses that are factually wrong — and human reviewers who can catch those errors help improve the reliability of the systems being trained.
The most effective approach is systematic: identify checkable claims, apply your domain knowledge, flag unsupported or suspicious content, and write specific feedback that explains what the problem is and why it matters for the user. Over time, this habit makes you faster, more consistent, and more valuable to AI training platforms.
Frequently Asked Questions
What does it mean to fact-check AI answers?
Fact-checking AI answers means identifying claims that are inaccurate, unsupported, or hallucinated. You check whether specific facts, dates, statistics, citations, and claims in an AI response are actually true before rating the response.
What is an AI hallucination?
An AI hallucination is a confident-sounding but false claim generated by an AI model. Examples include invented statistics, fake citations, wrong dates, and plausible-sounding explanations that are factually incorrect.
How do you spot hallucinations in AI answers?
Watch for very specific numbers without context, named sources that seem obscure or unverifiable, confident claims about rapidly changing topics, and explanations that sound authoritative but contradict common knowledge.
Are fact-checking skills useful for remote AI training jobs?
Yes. Many AI evaluation platforms test fact-checking ability during assessments because it is one of the core skills for model evaluation work. Platforms like Outlier AI, Mercor, Handshake AI, and micro1 all value reviewers who can distinguish accurate from inaccurate AI outputs.