
AI model evaluation is the process of having human experts judge whether an AI system's outputs are accurate, helpful, safe, well-reasoned, and aligned with what users actually need. It is one of the most important jobs in modern AI development — and increasingly, it is a job that rewards writers, researchers, and domain experts more than it rewards generic applicants.
Companies building large language models — the systems behind ChatGPT, Claude, Gemini, Grok, Llama, and every major AI assistant — cannot train those models on human judgment without humans actually providing that judgment. AI model evaluators are the people who supply it. If you can read carefully, assess quality honestly, and explain your reasoning clearly, you have the foundation for this kind of work.
This guide explains what AI model evaluation is, which roles exist, how the work is structured day-to-day, and how writers, researchers, and domain experts can position themselves to get hired.
What AI Model Evaluation Is and Why It Matters
When a company trains a large language model, it cannot rely entirely on automated metrics to know whether the model is actually good. Automated tests can measure whether a model gets a math problem right or matches a known answer on a benchmark — but they cannot reliably measure whether a response is genuinely helpful, whether the reasoning makes sense, whether the tone is appropriate for a sensitive topic, or whether a medical explanation is safe for a non-expert to read.
Human evaluators answer those questions. They are the quality signal that automated systems cannot produce on their own.
AI model evaluation encompasses several related activities:
- Comparing two model outputs and identifying which is better, and why
- Scoring responses against detailed rubrics covering accuracy, helpfulness, safety, tone, and completeness
- Writing explanations of quality differences that the AI company can use to refine future training
- Identifying factual errors, hallucinations, or gaps in reasoning
- Flagging safety issues, harmful content, or policy violations
- Creating examples of ideal behavior that the model should learn from
Human evaluators are not just quality checkers. They are active participants in shaping how AI systems respond. Every high-quality evaluation that correctly identifies a better answer, flags a subtle error, or explains a reasoning gap makes the AI a little more accurate, a little more useful, a little safer. That is why evaluation work is both genuinely useful and consistently in demand.
Key point: AI model evaluation is one of the few remote jobs where your years of professional expertise — as a marketer, salesperson, finance or business pro, writer, customer service lead, teacher, researcher, or any other specialist — translate directly into competitive advantage. The more specialized your knowledge, the more valuable your evaluations become.
Common AI Model Evaluation Roles
The evaluation field covers a range of specific role types, each requiring a slightly different skill emphasis. Understanding which roles exist helps you identify where your background positions you best.
1. Response Ranker / Preference Annotator
This is one of the most common evaluation roles. You receive a prompt and two or more model outputs, and you select the better one — then explain your reasoning in writing. The written rationale is critical: it teaches the model what made one response superior to the other. Preference annotation is foundational to the RLHF (Reinforcement Learning from Human Feedback) process that most major AI companies use to improve their models.
2. Rubric-Based Evaluator
You score AI outputs against a detailed criteria framework. The rubric might ask you to rate a response on dimensions such as factual accuracy, instruction following, helpfulness, safety, tone, appropriate uncertainty, and overall quality. Each dimension gets a separate score and, often, a short explanation. Rubric-based evaluation is more structured than pure preference ranking and rewards careful, consistent application of the scoring criteria.
3. Prompt Writer
You create inputs designed to test specific model capabilities or expose weaknesses. A prompt writer needs to understand what good model behavior looks like in order to write prompts that effectively reveal when behavior falls short. This role requires both creativity and precise thinking — you are deliberately designing the test, not just taking it.
4. Domain Expert Reviewer
You use specialized professional knowledge in law, medicine, finance, coding, science, education, or another field to evaluate outputs that a general reviewer cannot accurately judge. A general evaluator can tell whether a legal explanation sounds plausible — but only someone with legal training can identify whether it is actually correct, appropriately caveated, or dangerous in a specific jurisdiction. Domain expert reviewers typically qualify for higher-paying, more selective projects because their expertise cannot be faked.
5. Safety and Policy Evaluator
You identify outputs that violate content policies, safety guidelines, or ethical standards. Safety evaluation can involve reading outputs that contain or approach harmful content, so some platforms provide additional resources and support structures for this work. Clear judgment and consistent policy application are the core skills here.
6. Instruction-Following Reviewer
You judge whether the model completed exactly what the user asked, accounting for all constraints in the prompt. This requires close reading of both the instruction and the response — catching cases where the model answered a slightly different question, missed a format requirement, ignored a word limit, or failed to respect a constraint that was specified clearly. Attention to detail is the primary skill for this role.
7. Red-Teaming Contributor
You deliberately probe the model to find failure modes, harmful outputs, or logic gaps. Red-teaming is adversarial by design — you are trying to break the model or find its limits. This role requires creative thinking, persistence, and a clear understanding of what good model behavior looks like so you can recognize its absence. Red-teaming projects are often more selective and typically well-compensated.

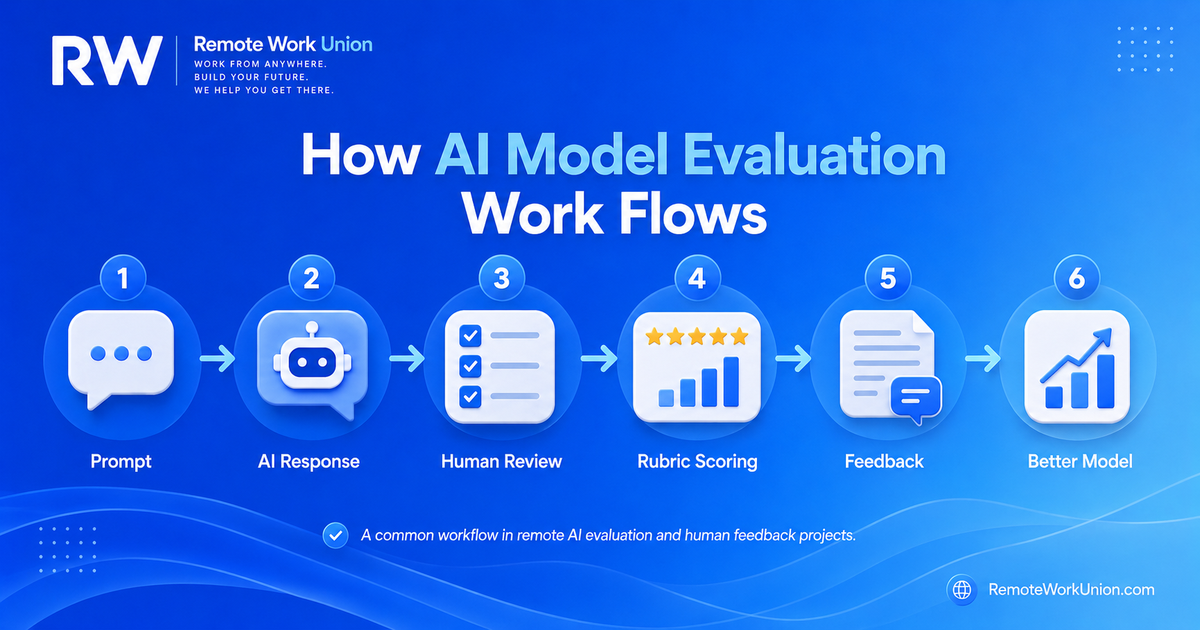
How AI Model Evaluation Works (The Process)
Every evaluation project starts with a detailed guideline document. This is the single most important artifact in the entire process. Guidelines define quality — what counts as a better answer, how to score different dimensions, what edge cases look like, how to handle ambiguous situations, and what language to use when explaining decisions. They may be ten pages long or more than one hundred pages, depending on the project's complexity.
The process typically unfolds like this:
- Guideline review. You receive the project guidelines before any paid work begins. Some projects require you to pass a certification or calibration exercise demonstrating that you have understood and internalized the guidelines correctly.
- Project-specific onboarding. Often includes example tasks with model answers, so you can see exactly what high-quality evaluation looks like for this specific project. Onboarding quality varies by platform — some are excellent, some are minimal.
- Qualification task. You complete a set of test evaluations that are reviewed against a gold standard. Your agreement rate with the gold standard determines whether you pass into paid work. Read the guidelines before attempting qualification — this is where applicants who skimmed fail.
- Paid work begins. Once qualified, you receive task batches and work through them within the project's deadlines. Your evaluations are reviewed continuously for quality.
- Ongoing quality measurement. Most platforms monitor your accuracy throughout the project, not just at qualification. If your scores drift below the threshold, you may receive calibration feedback or be asked to requalify.
Your job throughout this process is to internalize the guidelines and apply them consistently — not to substitute your personal judgment for the project's criteria. The most common failure mode for experienced evaluators is letting their own opinions override the rubric. The guidelines are the standard. Your job is to apply them accurately.

The Day-to-Day Workflow
On a typical evaluation session, the workflow looks like this: open your task batch, read the prompt and the model outputs, apply the rubric or make your preference selection, write your explanation if required, and submit. Most evaluation platforms are asynchronous — you work at your own pace within the project's deadlines, without a supervisor watching in real time.
The rhythm of evaluation work depends heavily on the task type. Response ranking tasks can move quickly once you are calibrated — reading, judging, explaining, moving on. Rubric-based tasks take more time per item because you are scoring multiple dimensions and writing a more detailed justification. Domain expert tasks often take the most time because they require deeper engagement with the content before you can accurately evaluate it.
Most evaluators find that the first few sessions on a new project are the most demanding — the guidelines are new, the task format is unfamiliar, and you are still building intuition for what high-quality evaluation looks like on this specific project. Quality tends to improve significantly after the first ten to twenty tasks. Give yourself time to calibrate before judging whether a project is a good fit for you.
Feedback from quality reviewers is a normal and expected part of the workflow. When you receive feedback on a specific evaluation, treat it as signal — it is telling you exactly how to improve. Evaluators who engage with feedback carefully and adjust their approach tend to qualify for better projects and receive more work over time.
Remote Work Union connects writers, researchers, and domain experts to legitimate AI model evaluation roles. Apply for free.
Find Roles Hiring Now →Which Skills Evaluation Rewards Most
AI model evaluation is a knowledge-work skill set. The skills that matter most are not technical — they are cognitive and professional.
- Precise writing. Many evaluation tasks require you to explain your decisions in writing. The explanation needs to be specific, concise, and grounded in the rubric language. Vague justifications — "Response A is better because it's clearer" — are less useful than precise ones: "Response A directly addresses the question posed, while Response B introduces unrequested information and fails to provide the specific figure the prompt asked for."
- Rubric discipline. Applying evaluation criteria consistently regardless of personal preference or opinion. If the rubric says to prioritize completeness over conciseness, you apply that even when your personal preference leans toward brevity. Rubric discipline is harder than it sounds and is the primary skill that separates strong evaluators from weak ones.
- Domain expertise. For specialized review work, genuine professional knowledge is the differentiating factor. A general evaluator cannot accurately assess whether a legal argument is sound, whether a medical recommendation is safe, or whether a financial projection is reasonable. Domain experts can — and that makes their evaluations worth more.
- Reading comprehension. Catching subtle quality differences between two responses that are both superficially acceptable. This requires close reading — noticing what is actually said versus what was asked, what is implied versus what is stated, what is supported versus what is claimed.
- Patience with edge cases. Evaluation projects regularly surface situations the guidelines do not clearly address. How you handle those cases — by returning to the guidelines, applying the closest analogous rule, and flagging the ambiguity — is as important as how you handle straightforward tasks.
- Self-management. Working independently without constant supervision. Most evaluation platforms are asynchronous and do not monitor your session in real time. The discipline to work carefully through a long task batch without drifting in attention or consistency is a genuine professional skill.
How Writers Benefit from Evaluation Work
Writers have structural advantages in AI model evaluation that are often underestimated. The core skill in evaluation — judging whether a written response is good — is something writers practice constantly. They already think about structure, tone, clarity, precision, and the difference between an answer that sounds good and an answer that actually is good.
When a writer reads two AI responses and is asked to decide which is better, they are doing something very similar to editing. They notice when a sentence is unnecessarily complicated, when a claim is made without support, when the tone shifts inappropriately, when the response answers a slightly different question than the one asked. These observations, translated into evaluation language, are exactly what high-quality evaluation looks like.
Writers also have an advantage in the explanation component of evaluation tasks. Writing a clear, specific justification for why you preferred one response over another is a writing task. It rewards people who can communicate precise observations in a way that another person can understand and trust.
For writers looking to enter AI evaluation work, the key is to translate their existing language into the specific vocabulary of evaluation. Instead of saying "I'm a good editor," frame it as: "I can evaluate AI responses for instruction following, factual accuracy, tone consistency, and reader usefulness." That translation makes your skills visible to platforms that are matching applicants to projects.
How Researchers and Domain Experts Benefit
Researchers and domain experts occupy the highest-value tier of the AI evaluation market. Their advantage is not just that they know things — it is that they can identify the specific ways that AI outputs fall short when those failures require genuine expertise to detect.
A general evaluator can tell that a response about securities law sounds authoritative. A lawyer can tell whether it is actually correct, whether it appropriately accounts for jurisdictional differences, and whether it contains advice that could mislead a non-expert in a harmful way. That difference is not a matter of degree — it is categorical. Some evaluation errors simply cannot be caught without the relevant expertise.
This is why companies working on AI for specialized domains actively seek out domain experts. They need evaluators who can catch the errors that automated systems and general reviewers miss. The evaluation work done by these specialists directly shapes whether an AI system can safely and accurately serve professionals in that field.
Researchers bring a different but equally valuable advantage: the ability to identify hallucinations, unsupported claims, and surface-level reasoning that passes casual review but fails deep inspection. A researcher who works with primary sources every day knows the difference between a response that correctly summarizes a finding and one that fabricates a plausible-sounding but nonexistent result. That detection skill is exactly what AI companies need.
For researchers and domain experts, the application strategy is specificity. The more precisely you describe what you can evaluate — not just "legal knowledge" but "contract law, employment law, and regulatory compliance review for U.S. jurisdictions" — the easier it is for a platform to match you to a project where your expertise genuinely matters.
How to Find AI Model Evaluation Jobs
The AI evaluation job market has expanded significantly as more companies train and maintain large language models. Here is where to look and what to search for.
Search terms that work:
- AI model evaluation jobs remote
- AI evaluator jobs
- LLM evaluator jobs
- response ranker jobs
- AI preference annotator
- expert review AI jobs
- RLHF evaluator jobs
- AI response reviewer jobs
- work from home AI evaluator
Platforms actively hiring evaluators:
- Handshake AI — focuses on expert and research-adjacent evaluation roles, and is often one of the fastest ways to get started.
- Mercor — matches workers to AI evaluation and expert review projects, often with higher pay rates for domain experts.
- micro1 — AI-interview matching for expert AI training and evaluation projects, with specialist rates up to $50–$200/hr.
- Outlier AI — one of the largest platforms for AI training and evaluation tasks. Accepts applicants globally across many domains and languages.
- Scale AI — works with contractors across a range of evaluation and annotation task types, particularly for enterprise AI clients.
- Appen — a long-established platform with ongoing evaluation projects in many languages and domains.
- DataAnnotation.tech — offers flexible AI training and evaluation tasks with task-based pay.
- Prolific — used for research-oriented evaluation tasks, particularly in academic and behavioral AI research contexts.
- Surge AI — focuses on natural language evaluation tasks for AI training.
Direct company programs: Some AI labs — including Anthropic, Google DeepMind, OpenAI, and Meta AI — also work with contractors through staffing firms for more specialized evaluation projects. These roles tend to be more selective and often require domain expertise or professional credentials. They may not always appear on public job boards, but they are worth researching directly through company careers pages and contractor networks.
How to Position Yourself Effectively
The difference between an evaluation application that gets noticed and one that does not is almost always specificity. Generic descriptions — "I'm detail-oriented," "I have strong writing skills," "I have a background in healthcare" — tell a platform very little about what you can actually evaluate and how accurately you can do it.
Effective positioning translates your background into evaluation language that platforms can act on immediately.
Instead of: "I'm a good writer."
Say: "I can evaluate AI responses for instruction following, factual accuracy, organizational clarity, and reader usefulness. I can identify when a response answers a slightly different question than the one asked."
Instead of: "I have legal experience."
Say: "I can review AI-generated legal reasoning for factual accuracy, appropriate jurisdictional caveats, and the kinds of oversimplifications that could mislead a non-lawyer."
Instead of: "I work in finance."
Say: "I can evaluate AI-generated financial explanations for accuracy in valuation concepts, appropriate risk disclosures, and the distinction between investment education and investment advice."
Instead of: "I'm a researcher."
Say: "I can identify hallucinated citations, unsupported empirical claims, and the difference between a response that accurately summarizes a finding and one that extrapolates beyond what the evidence supports."
This kind of specificity makes you immediately matchable. A platform looking for someone to evaluate AI outputs in your domain can see exactly what you can do — and more importantly, they can see that you understand what evaluation actually requires.
Tip: Apply to multiple platforms simultaneously. Project availability varies by platform and timing — a platform with no work this week may have active projects next month. Qualifying on three or four platforms dramatically reduces income volatility compared to depending on one.
Frequently Asked Questions
Do I need AI experience to get an evaluation job?
No. Domain expertise, writing ability, and careful judgment are often more valuable to an AI evaluation platform than familiarity with AI specifically. Platforms are looking for people who can accurately assess whether a model's output is correct, helpful, and well-reasoned — and that requires subject matter knowledge far more than AI background. A marketer, salesperson, financial analyst, business operator, customer service lead, lawyer, doctor, or researcher with no prior AI work experience can qualify for expert evaluation roles that someone with generic AI familiarity cannot.
How is evaluation different from basic annotation?
Annotation can be more categorical and repetitive — labeling text, classifying images, transcribing audio. Evaluation typically requires more qualitative judgment and written explanation. When you evaluate a model response, you are not just categorizing it — you are assessing its accuracy, reasoning, helpfulness, safety, and tone, and then articulating why it does or does not meet the standard. The written explanation component is what separates evaluation from simpler annotation tasks.
Can evaluation work be done part-time?
Yes. Most AI model evaluation projects are asynchronous, meaning you work through task batches at your own pace within the project's deadlines. This structure is well-suited to part-time, supplemental, or flexible schedules. Many evaluators work a few hours per day around other commitments.
How much does AI model evaluation pay?
Pay varies significantly by domain, platform, task complexity, and the expertise required. General evaluation tasks — comparing two responses and selecting the better one — typically pay less than specialized expert review in areas like law, medicine, finance, or advanced mathematics. The highest-paying evaluation roles go to applicants who can demonstrate genuine domain expertise and consistent high-quality judgment, with specialized expert review reaching up to $50–$200/hr.
What happens if my evaluations are rejected?
Most platforms provide feedback explaining why specific evaluations were flagged as below standard. This feedback almost always centers on rubric alignment and instruction-following — either your decisions did not match the project's criteria, or you missed constraints in the task prompt. Take the feedback seriously, identify the specific pattern, and apply the correction to future tasks. Many platforms allow you to requalify after a calibration period.
Which platforms offer the best AI model evaluation jobs?
Platforms actively hiring AI model evaluators include Handshake AI, Mercor, micro1, Outlier AI, Scale AI, Appen, DataAnnotation.tech, Prolific, and Surge AI. Some AI labs also work with contractors through staffing firms for more specialized evaluation projects. The best approach is to apply to multiple platforms simultaneously, since project availability varies by platform and timing.
Final Takeaway
AI model evaluation is not just a side hustle — it is skilled knowledge work that happens to be remote and flexible. Marketers, salespeople, finance and business professionals, customer service leads, writers, researchers, educators, lawyers, doctors, and other domain experts have advantages that generic AI enthusiasm cannot replace. The demand for this work is not going away: every new model generation requires evaluation, every expanded capability requires testing, and every domain expansion requires people with genuine expertise in that domain.
If you can explain why one answer is better than another — specifically, in writing, and consistently over many tasks — you have the core skill. The rest is guideline study, rubric discipline, and applying the same careful attention to every task that you would give to professional client work. That combination is what the best evaluation jobs are looking for, and it is more accessible than most applicants assume.