
In many remote AI training jobs, the task is not just choosing Answer A or Answer B. The valuable part is explaining why one answer is better. A strong explanation tells the model team what changed: which answer followed the prompt, which one was more accurate, which one was clearer, and which one helped the user more.
This article gives a practical framework for writing better comparison explanations in AI model evaluation, RLHF rating, response ranking, chatbot review, and other remote AI work on platforms like Outlier AI, Mercor, Handshake AI, and micro1. The goal is not to sound academic. The goal is to be precise, fair, and useful.
Why This Skill Matters in AI Training Jobs
AI companies rely on human reviewers because answer quality is not always obvious from a simple score. Two responses can both look polished, but one may follow the instructions better, avoid a factual mistake, handle uncertainty more responsibly, or solve the user's actual problem with less friction.
That is why explanation writing matters for remote AI evaluator jobs. Whether a task is connected to ChatGPT-style systems, Claude-style assistants, Gemini-style products, Grok-style answers, or internal large language model testing, human feedback helps teams understand what the model should do more often. For applicants on evaluation platforms, this is a core skill: compare two answers, identify the winner, and explain the reason in plain language.
The Difference Between Picking a Winner and Explaining a Winner
A weak evaluator says: "Answer B is better because it is clearer." That may be true, but it is incomplete. It does not explain what made it clearer, why that matters, or whether any other criteria were important.
A stronger evaluator says: "Answer B is better because it follows the user's request for a step-by-step plan, includes specific actions, and avoids the unsupported claim in Answer A. This makes it more useful and safer for the user, even though Answer A has a slightly shorter introduction."
The second explanation is better because it includes a verdict, criteria, evidence, and user impact. It also shows nuance by acknowledging a smaller strength in the weaker answer.
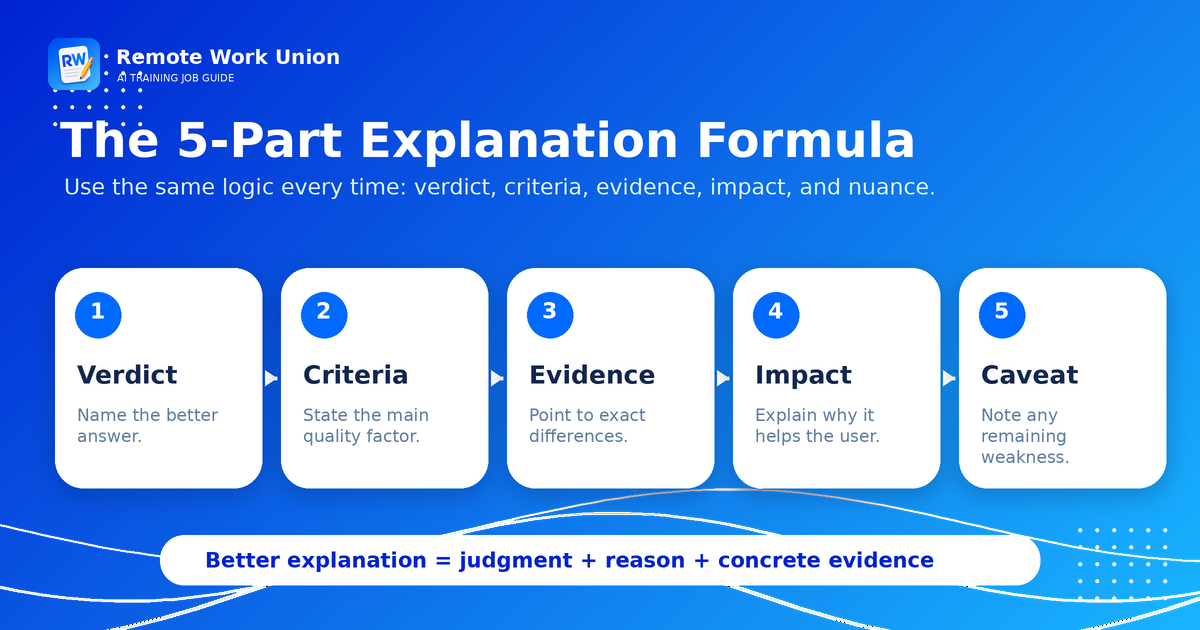
Use the Five-Part Explanation Formula
When you compare two AI responses, use this structure: verdict, criteria, evidence, user impact, and caveat. You do not need to write a long paragraph every time, but you should include the pieces that make your judgment understandable.
- Verdict: State which answer is better. Do this directly. Avoid hiding the decision inside vague language.
- Criteria: Name the main reason. Common criteria include instruction-following, accuracy, completeness, clarity, relevance, safety, formatting, and usefulness.
- Evidence: Point to a concrete difference between the two answers. Mention what one answer includes, misses, invents, or handles better.
- User impact: Explain why that difference matters for the person who asked the question. The best answer is usually the one that helps the user complete the task with fewer mistakes or less confusion.
- Caveat: If the weaker answer does something well, say so. If the better answer has a flaw, mention it. Balanced feedback is more credible than one-sided feedback.
The Main Criteria AI Evaluators Should Use
Instruction fit: Did the answer do what the user asked? This includes format, scope, tone, constraints, and any specific requirements. If the user asked for three bullet points, an answer with seven paragraphs may be less aligned even if it contains good information.
Accuracy: Does the answer avoid false, unsupported, or misleading claims? Accuracy is especially important for finance, legal, medical, technical, hiring, travel, and safety-related prompts. A clear answer is not better if it is confidently wrong.
Completeness: Does the answer cover the important parts of the request? A response can be concise and still complete, but it should not skip the core question.
Clarity: Is the answer easy to understand? Look for structure, plain language, logical order, and whether the response avoids unnecessary complexity.
Usefulness: Does the answer help the user take the next step? In many AI response ranking tasks, usefulness is the tie-breaker between two generally correct answers.
Safety and responsibility: Does the answer avoid harmful instructions, overconfident claims, privacy violations, or risky advice? The safest answer is not always the shortest answer; it is the one that handles risk appropriately.

A Simple Example of a Strong Explanation
Prompt: "Write a short email asking my manager to move our meeting from 2 PM to 4 PM because I have a doctor appointment."
Answer A writes a long email, apologizes repeatedly, and says the doctor appointment is urgent even though the user did not say that. Answer B writes a short, polite email that asks to move the meeting and keeps the reason simple.
Strong explanation: "Answer B is better because it follows the user's request for a short email, keeps the tone professional, and does not add unsupported details about the appointment being urgent. Answer A is polite, but it is too long for the request and invents a stronger reason than the user provided. B is more accurate to the prompt and easier for the user to send."
Tip: Good feedback is specific enough that someone could improve the weaker answer from your note alone. Instead of saying "A is bad," identify the repair: A needs to remove unsupported details, answer the second part of the prompt, use the requested format, or explain uncertainty more clearly.
Remote Work Union connects you to legitimate remote AI evaluation roles where these skills are tested. Apply for free to find roles hiring now.
Find Roles Hiring Now →Useful Phrases for AI Answer Comparisons
These phrases can help you structure comparisons without defaulting to vague language:
- "Answer B is stronger because it directly addresses the user's main question before adding context."
- "Answer A is less helpful because it misses the requested format and adds unrelated information."
- "Both answers are mostly correct, but B is better because it handles the user's constraint more carefully."
- "A has a clearer opening, but B provides more accurate and actionable guidance overall."
- "The main issue with A is not tone; it is that it introduces an unsupported claim."
- "B is the better response because it gives a complete answer while staying within the scope of the prompt."

Common Mistakes to Avoid
Do not rely on personal preference. "I like B better" is not useful unless you tie it to a criterion such as clarity, accuracy, or instruction-following.
Do not overvalue length. A longer answer is not automatically more complete. A shorter answer is not automatically clearer. Judge whether the length fits the user's request.
Do not ignore small factual errors. In AI model evaluation work, a single unsupported claim can make an otherwise polished answer worse.
Do not punish a safe answer for being cautious when caution is appropriate. For medical, legal, financial, or high-risk advice, uncertainty and boundaries can improve answer quality.
Do not write feedback that only repeats the score. The explanation should justify the score, not restate it.

Frequently Asked Questions
What makes a strong explanation in AI response comparison tasks?
A strong explanation includes a verdict (which answer is better), the main criterion (accuracy, instruction-following, completeness, clarity), concrete evidence from the responses, and the user impact of the difference. Mentioning a caveat when the weaker answer does something right also strengthens the explanation.
What criteria should AI evaluators use when comparing answers?
The main criteria are instruction fit, accuracy, completeness, clarity, usefulness, and safety. Instruction fit is often the most important: did the answer do what the user asked? Accuracy matters most in high-stakes domains like medical, legal, and financial topics.
How do AI platforms use human comparison explanations?
AI training platforms use human comparison feedback as training signal. Your explanation helps the system understand not just which answer won, but why — so future model outputs can better match user intent, accuracy standards, and safety requirements.
Should I mention strengths of the weaker answer in my feedback?
Yes. Acknowledging what the weaker answer does well (a caveat) makes your feedback more credible and balanced. It shows you evaluated both answers fairly rather than just picking a winner and ignoring the nuance.