
AI models can state false information with the same confidence as true information. When a model invents a statistic, fabricates a citation, or gets a date wrong and presents it as established fact, that is a hallucination. Catching it is one of the most valuable skills a remote AI evaluator can have.
Platforms like Outlier AI, Mercor, Handshake AI, and micro1 regularly test applicants on their ability to identify inaccurate AI outputs. This guide explains what counts as a hallucination, gives five concrete red flags to watch for, walks through a detection workflow, and shows how to write useful hallucination feedback.
What Counts as an AI Hallucination
A hallucination is a confident false claim. It is not the same as an opinion, a simplification, or an appropriate caveat. The defining feature is that the AI presents invented or inaccurate information as though it were established fact.
Hallucinations include: invented statistics cited as specific facts, fabricated citations or non-existent sources, wrong dates presented with confidence, incorrect locations or eligibility rules stated as definitive, and names that almost match real people or organizations but contain subtle errors.
Hallucinations do not include: hedged estimates ("this may vary"), opinions clearly framed as opinions, simplified explanations that are directionally accurate, or appropriate uncertainty language ("as of my last update"). Those are signs of good epistemic practice, not failures.

Five Hallucination Red Flags
Red Flag 1: Confident language without supporting evidence. Phrases like "studies show," "research confirms," "it is well established that," or "according to experts" followed by a specific claim but no named source are a warning sign. Real evidence has a source. Hallucinated evidence sounds authoritative but cannot be traced.
Red Flag 2: Fake or unverifiable citations. A model may generate a plausible author name, journal title, and year. The citation looks real but the source cannot be found. When a response includes a named source that seems obscure, search for it. If it does not exist, flag it as a hallucinated citation.
Red Flag 3: Precise numbers without grounding. Oddly specific statistics like "43.7% of respondents" or "a $2.3 trillion market" without any named study or data source are common hallucination markers. Precise numbers suggest verified research, but in an AI response they may be entirely made up.
Red Flag 4: Wrong dates, locations, or eligibility rules. Dates for historical events, product releases, legislation, or company milestones may be off by years or invented entirely. Location-specific rules (like visa eligibility, tax law, or employment requirements) are also common hallucination targets because they vary and change frequently.
Red Flag 5: Names that almost match. A model may name an organization, person, publication, or product that is close to something real but slightly wrong. "The National Institute for Labor Research" may sound credible but not exist. These near-misses are easy to miss because they sound plausible on first read.
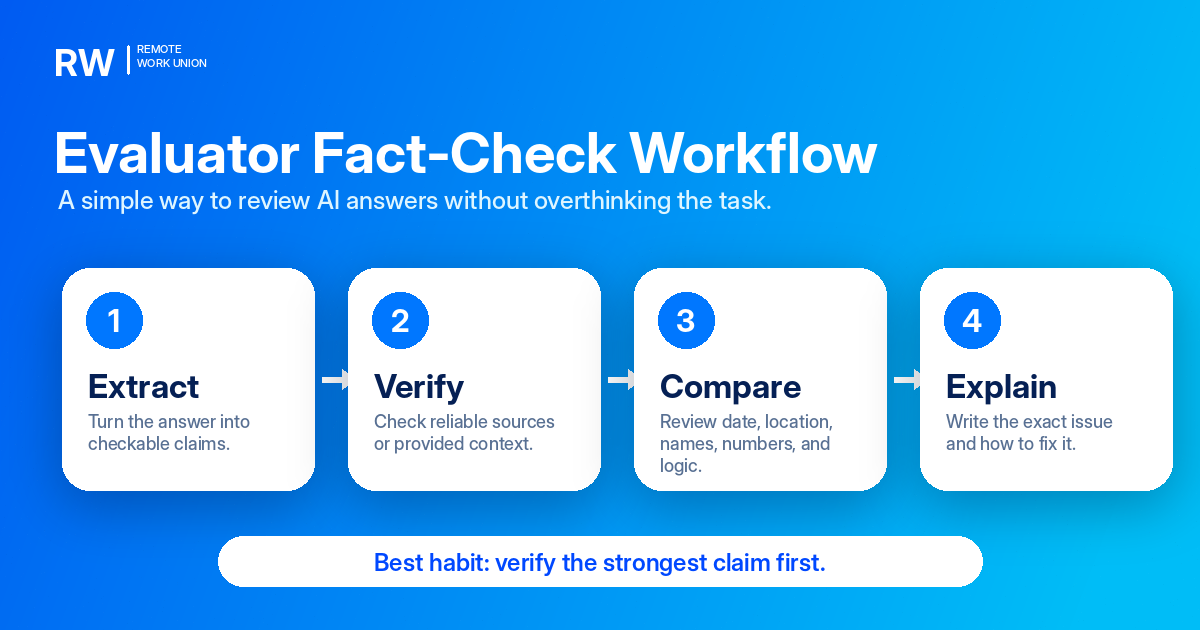
The Hallucination Detection Workflow
Use the same structured approach every time:
- Extract specific claims. Read the response and mark any factual assertion: dates, statistics, citations, named organizations, eligibility rules, technical claims, and confident generalizations.
- Prioritize the claims that matter most. A hallucinated central claim is more serious than a hallucinated background detail. Focus first on claims that would change the user's understanding or action if they were wrong.
- Check what you can verify. Search for named sources, dates, and specific facts. Apply your domain knowledge to claims in your area of expertise. Note when a claim cannot be verified rather than assuming it is correct.
- Look for internal contradictions. Sometimes a response contradicts itself. A hallucination may conflict with another part of the same answer, with information given in the task, or with widely known facts.
- Assess severity. Is the hallucination peripheral (does not affect the core answer) or central (undermines the main response)? Is it in a high-stakes domain like medicine, law, or finance? Severity affects how much it should lower the rating.
- Write structured feedback. Name the issue, explain the evidence gap, describe the impact, and suggest the fix.
Hallucination Examples
Example 1 — Invented statistic: An AI response says "According to a 2023 McKinsey report, 68% of remote AI training workers earn above minimum wage." A search finds no such McKinsey report. This is a hallucinated citation with a fabricated statistic. The response should receive a significant accuracy penalty.
Example 2 — Wrong date: A response states that a major data privacy law "went into effect in 2018 across all EU member states." The law in question actually applies in a different jurisdiction and under different conditions. This is a confident wrong claim about a specific legal fact.
Example 3 — Near-miss organization name: A response cites "The American Institute of AI Professionals" as a credentialing body. No such organization exists. The name sounds plausible because it echoes the style of real professional associations.
Example 4 — Confident universal rule that varies: A response states that contractors in the United States "are not eligible for unemployment benefits under any circumstances." This is wrong. Eligibility varies by state and situation. The response states a false universal rule as established fact.
How Hallucinations Affect HAS Ratings
Many AI evaluation platforms use a Helpfulness-Accuracy-Safety (HAS) framework. Hallucinations directly affect the Accuracy dimension but can also affect Helpfulness and Safety depending on the context.
A hallucinated fact in a response about travel tips is a moderate accuracy problem. A hallucinated medical dosage, legal eligibility rule, or financial regulation is a high-severity issue that should significantly lower both accuracy and safety ratings, because acting on that false information could harm the user.
Remote Work Union connects you to legitimate remote AI evaluation roles where hallucination detection is valued. Apply for free to find roles hiring now.
Find Roles Hiring Now →How to Write Hallucination Feedback
Use a four-part structure: issue, evidence gap, impact, and fix.
Issue: Name the specific claim that is hallucinated. "The response cites a specific study from 2022 claiming that 71% of AI evaluators work fewer than 10 hours per week."
Evidence gap: Explain why it is unsupported. "This study cannot be found and the source name does not match any known research institution."
Impact: Explain why it matters to the user. "A user reading this may believe a specific statistic has been verified when it has not, and may repeat it or act on it as though it were established fact."
Fix: Suggest what the model should have done. "The response should either cite a verifiable source or rephrase as an estimate: 'Many AI evaluators report working part-time hours, though exact figures vary.'"

What NOT to Mark as a Hallucination
Not every imperfect claim is a hallucination. Avoid over-flagging these legitimate patterns:
- Hedged estimates: "Rates typically range between..." is not a hallucination. The model is making a reasonable estimate without claiming it is verified fact.
- General knowledge stated simply: Simplifying a complex topic is not hallucination. If the core direction is accurate, a simplified explanation may be appropriate for the audience.
- Opinions framed as opinions: "Some experts argue..." or "One perspective is..." is not a hallucinated fact. It is a framed viewpoint.
- Uncertainty framing: "As of my last update," "this may have changed," or "check current regulations" is good epistemic practice, not a hallucination.
- Outdated information clearly about the past: A response that describes a policy correctly as it existed in 2022 is not hallucinating just because the policy changed in 2024. Evaluate based on whether the response handles temporal uncertainty appropriately.
Tip: The key question is always: did the model present invented or false information as established fact? If yes, flag it. If the model hedged, estimated, or framed uncertainty correctly, that is not a hallucination.
Quick Checklist Before Submitting
- Did I identify all specific factual claims in the response?
- Did I check the claims that would most affect the user if wrong?
- Did I look for precise numbers, named sources, specific dates, and location rules?
- Did I search for any named citations that seemed unusual?
- Did I distinguish between hallucinations and appropriate uncertainty?
- Did my feedback name the specific claim, explain the evidence gap, describe the impact, and suggest the fix?
- Did my rating reflect the severity of the hallucination given the domain and user stakes?
Frequently Asked Questions
What counts as an AI hallucination?
An AI hallucination is a confident-sounding claim that is false or unverifiable. It includes invented statistics, fabricated citations, wrong dates or names, incorrect locations, and plausible-sounding statements that contradict reality. The key feature is that the AI presents the claim as fact without any real basis.
What are the biggest red flags for AI hallucinations?
The five main red flags are: confident language without supporting evidence, fake or unverifiable citations, very precise numbers without a named source, wrong dates or eligibility rules stated as definitive, and names that almost match real entities but contain subtle errors.
What should I NOT mark as a hallucination?
Do not flag opinions, stylistic choices, cautious hedging, or simplified explanations as hallucinations. Also do not flag claims that are uncertain but appropriately framed as uncertain. A hallucination is a confident false claim, not a guess presented as a guess.
How do I write feedback for a hallucinated AI answer?
Use the four-part feedback structure: name the issue (the hallucinated claim), explain the evidence gap (why the claim is unsupported), describe the impact (why this matters for the user), and suggest the fix (what the model should have said instead or how it should have hedged).